안녕하세요! 코크리 크리에이터 김보경입니다🙋🏻♀️
드디어 기다리고 기다리셨던 모두가 할 수 있는 데이터분석 1편입니다!
어떤 콘텐츠인가요?
해당 콘텐츠는 데이터 분석시 EDA를 하면서 그리는 그래프에 대한 정의와 해당 그래프가 의미하는 바는 무엇인지에 대한 기초적인 내용이 포함되어있습니다. 저도 가장 처음에 데이터를 다룰때 그래프를 이해하려고 했던 방식 그대로 해당 수치가 어떤걸 의미하는지, 그래프에서 어떤 인사이트를 발견하는지에 대해 공유하고자 합니다.
왜 공유 자전거 데이터셋인가요?
평소에도 이동과 관련하여 관심을 갖고 있었고 최근 배달산업으로 이직을 하면서 라이더나 배달 관련 데이터로 분석을 하려했습니다만, 괜찮아 보이는 데이터를 발견했는데 아쉽게도 데이터셋이 비공개 되어있어서 해당 산업에 대한 데이터 대신 공유 자전거에 대한 데이터로 진행하고자 합니다.
데이터셋 설명
==========================================
Bike Sharing Dataset
==========================================
Hadi Fanaee-T Laboratory of Artificial Intelligence and Decision Support (LIAAD), University of Porto INESC Porto, Campus da FEUP
Rua Dr. Roberto Frias, 378
4200 - 465 Porto, Portugal
자전거 공유 시스템은 회원 가입, 대여, 반납 등 모든 과정이 자동화된 대여 시스템이며, 이걸 통해 사용자는 특정 위치에서 자전거를 쉽게 대여하고 반납할 수 있습니다.
현재 전 세계적으로 약 500개가 넘는 공유 자전거 시스템이 있으며 50만 개가 넘는 자전거로 구성되어 있다고합니다. 한국에서는 서울시 따릉이가 대표적인 예라고 할 수 있습니다. 따릉이를 이용해보신 분들이 계시다면 아시겠지만 이동하는 경로, 출발 및 도착 위치가 앱 내에 표시되는 것을 확인할 수 있습니다. 이 모든게 데이터로 쌓이고 있습니다.
공유 자전거 시스템은 환경 및 계절에 따라 영향을 받는 비즈니스이며, 날씨, 강수, 요일, 계절, 시간에 따라 수요에 큰 편차가 있습니다. 오늘처럼 비가 오는 날에는 자전거를 이용할 수 없으며, 너무 덥거나 너무 추운 날에는 자전거를 타고 이동하기 쉽지않으니까요!
이렇게 공유 자전거 데이터셋을 활용하여 간단하게 환경 및 계절, 시간에 따라 매일 자전거 대여 횟수를 예측해보고 특정 이벤트가 발생한 적이 있는지 데이터를 통해 이상 징후나 이벤트 여부를 파악해볼 예정입니다.
데이터 명세
hour.csv : 시간 단위로 집계된 자전거 공유 횟수 (17379시간)
day.csv : 일 단위로 집계된 자전거 공유 횟수 (731일)
| 컬럼명 | 설명 |
| instant | 인덱스 |
| dteday | 날짜 |
| season | 계절 (1:겨울, 2:봄, 3:여름, 4:가을) |
| yr | 년(0:2011, 1:2012) |
| mnth | 월 (1 ~ 12) |
| hr | 시간 (0 ~ 23) : hour.csv에만 있는 컬럼 |
| holiday | 날씨가 휴일인지 아닌지 |
| weekday | 요일 |
| workingday | 근무일 (1:주말, 공휴일, 0:그 외) |
| weathersit | 날씨 표현 1: 맑음, 구름 적음, 부분적으로 흐림, 부분적으로 흐림 2: 안개 + 흐림, 안개 + 깨진 구름, 안개 + 적은 구름, 안개 3: 약한 눈, 약한 비 + 뇌우 + 산란 구름, 약한 비 + 산란 구름 4: 폭우 + 얼음 팔레트 + 뇌우 + 안개, 눈 + 안개 |
| temp | 정상 온도(섭씨) 값은 (t-tmin)/(tmax-tmin), tmin=-8, t_max=+39(시간 단위에서만)를 통해 도출 |
| atemp | 섭씨로 정규화된 느낌 온도 값은 (t-tmin)/(tmax-tmin), tmin=-16, t_max=+50을 통해 도출(시간 단위로만) |
| hum | 표준화된 습도 값은 100(최대)으로 나뉨 |
| windspeed | 풍속 값은 67(최대)로 나뉩니다. |
| casual | 캐주얼 사용자 수 |
| registered | 등록된 사용자 수 |
| cnt | 캐주얼 및 등록 자전거 모두를 포함한 총 대여 자전거 수 |
데이터 다루기
참고) 모든 코드에서 input은 >>로 표기했습니다.
day.csv 파일과 hour.csv 파일을 불러와서 데이터 프레임 형태로 만들어줍니다.
>> df_day = pd.read_csv('../input/rental-bike-sharing/day.csv')
info를 확인해보면, 731개의 row가 존재하며, 각 값에 null 값이 없다는 것을 확인할 수 있습니다.
>> df_day.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 731 entries, 0 to 730
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 instant 731 non-null int64
1 dteday 731 non-null object
2 season 731 non-null int64
3 yr 731 non-null int64
4 mnth 731 non-null int64
5 holiday 731 non-null int64
6 weekday 731 non-null int64
7 workingday 731 non-null int64
8 weathersit 731 non-null int64
9 temp 731 non-null float64
10 atemp 731 non-null float64
11 hum 731 non-null float64
12 windspeed 731 non-null float64
13 casual 731 non-null int64
14 registered 731 non-null int64
15 cnt 731 non-null int64
dtypes: float64(4), int64(11), object(1)
memory usage: 91.5+ KB
df_day 데이터프레임의 상위 5개의 데이터를 확인합니다. 대략 형태는 아래와 같으며, "season", "yr", "mnth", "weekday" 등 범주형 열임을 알 수 있습니다. 후에 수치형과 범주형을 분리해서 처리해야할 것 같습니다.
>> df_day.head()
그 다음에 각 값을 중복 제거했을때 몇개의 고유값을 가지고 있는지 확인합니다.
>> df_day.nunique()
각 데이터의 선택할 수 있는 경우에 따라 유니크값이 보여지는 것을 확인할 수 있습니다. season(계절) 컬럼은 4계절을 가지고 있기 때문에 유니크한 값이 4개이고 해당 데이터가 2011년과 2012년 기간의 데이터이기 때문에 yr(연도)도 유니크한 값이 2개입니다. 여기서 예상과 다르게 weathersit(날씨 표현)의 컬럼은 4개의 종류가 있지만 3개의 값만 존재하는 것을 확인할 수 있습니다.
instant 731
dteday 731
season 4
yr 2
mnth 12
holiday 2
weekday 7
workingday 2
weathersit 3
temp 499
atemp 690
hum 595
windspeed 650
casual 606
registered 679
cnt 696
dtype: int64
데이터를 처음 보는 것이다 보니 각 변수간의 관계를 알아보기 위해 heatmap을 그려줍니다. heatmap을 확인해보면 "instant", "yr", "season", "mnth", "temp", "atemp" 컬럼이 높은 상관관계를 가지고 있음을 알 수 있습니다. (+값은 양의 상관관계, -값은 음의 상관관계를 의미합니다.)
>> df_corr = df_day.corr()
fig, ax = plt.subplots(nrows = 1, ncols = 1, figsize = (25, 12))
sns.heatmap(df_corr, annot=True)
plt.show()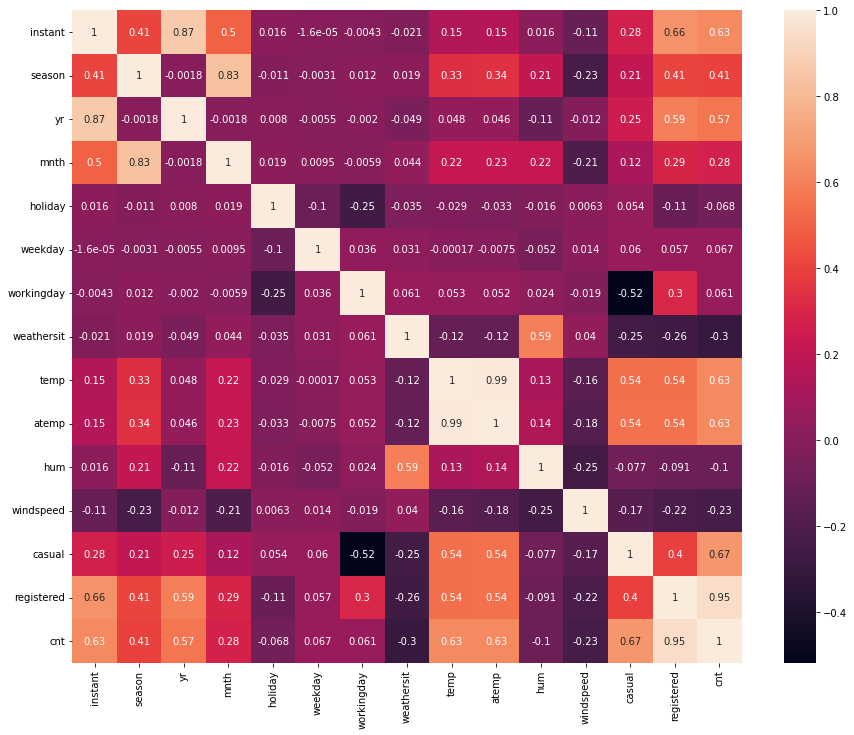
여기서 상관관계(correlation)란?
상관관계란 데이터 특성 간의 관계를 의미하며, 두 데이터가 어떤 관계에 있는지 파악하기위해 쓰입니다. 예를들어 "시험성적"과 "공부시간"의 어떠한 연관성이 있다면 상관관계가 있다 라고 표현합니다.
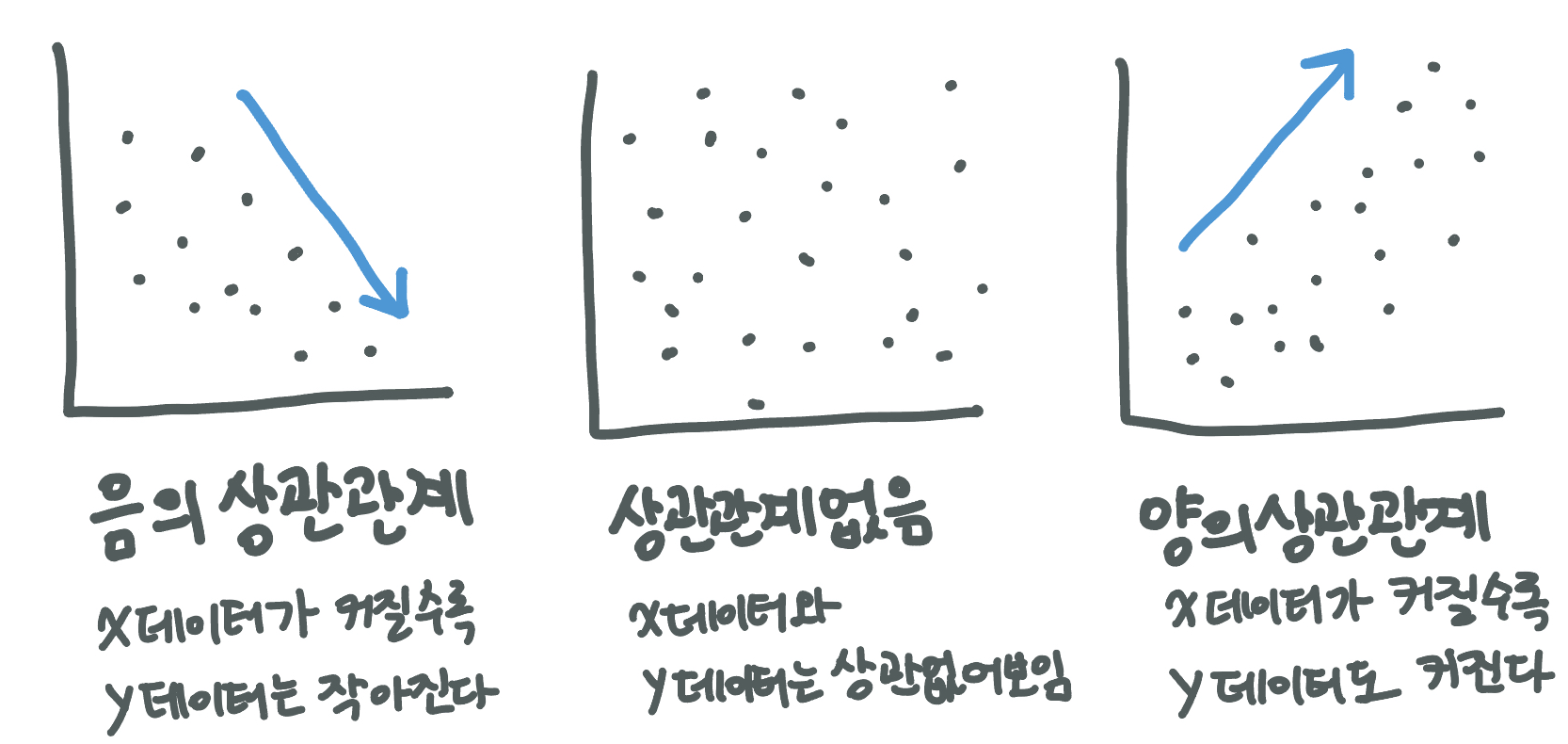
두 데이터 사이에 얼마나 관계가 있는지에 대한 값을 상관계수라고 표현합니다. 상관계수는 -1 ~ 1 사이의 값을 가집니다.
- 양의 상관관계(+) : "시험성적"과 "공부시간"의 상관계수가 0.6로 나타났다면 높은 양의 상관관계라고 할 수 있습니다.
- 음의 상관관계(-) : "시험성적"과 "게임시간"의 상관계수가 -0.4로 나타났다면 낮은 음의 상관관계라고 할 수 있습니다.
위에서 상관관계를 확인한 것 처럼 자전거라는 이동수단이 가장 많은 영향을 받는 부분은 온도(temp)일 것입니다. 그렇기 때문에 temp 컬럼에 대해서 우선 파악해보면 위에서 파악한 것 처럼 Null값이 없으며 25%, 50%, 75%로 분포를 대략 파악할 수 있습니다.
>> df_day['temp'].describe()count 731.000000
mean 0.495385
std 0.183051
min 0.059130
25% 0.337083
50% 0.498333
75% 0.655417
max 0.861667
Name: temp, dtype: float64위 분포를 통해 중위수(50%)가 0.49임을 알 수 있습니다. 수치로만 보았을때 정규분포를 따르는 것 처럼 보입니다. 전체 분포를 확인하기 위해 위 describe()값을 df_temp_desc 변수에 저장하여 distplot을 그려보았습니다.
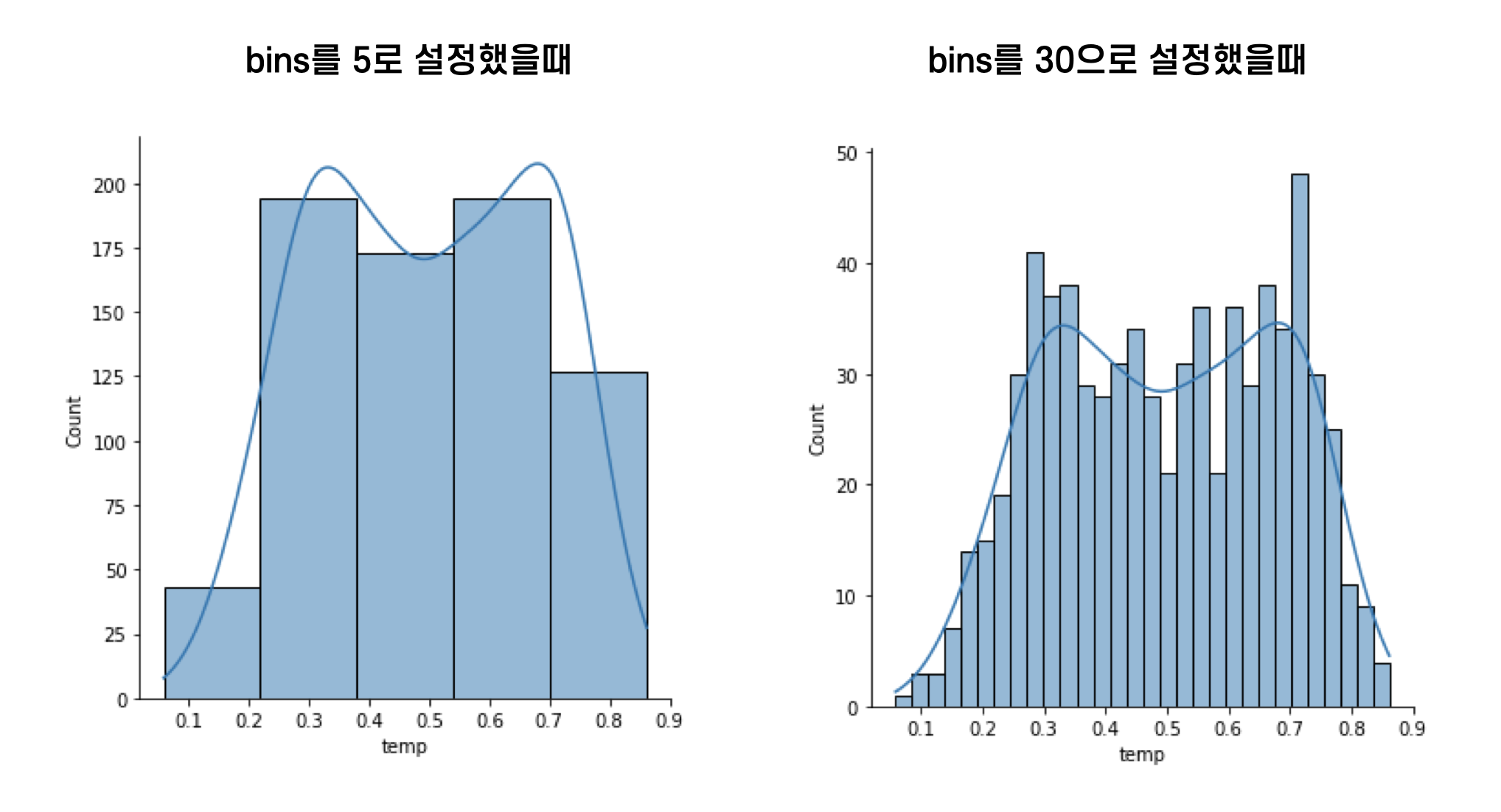
위에서 본 것처럼 분포값을 확인했을때 모든 값이 0 ~ 1 사이이기 때문에 정규 분포를 따르는 것처럼 보이지만 실제로 그래프를 그려보면 봉이 2개인 쌍봉분포를 취하고 있습니다. 두 개의 데이터 피크(peak)는 일반적으로 두 개의 서로 다른 그룹이 있다는 것을 나타냅니다. 추가로 고정된 4분위수 값을 그래프에 표현했습니다.
>> sns.displot(data = df_day, x = "temp", kde = True)
plt.axvline(df_temp_desc["25%"], ls="--", color='b')
plt.axvline(df_temp_desc["50%"], ls="--", color='b')
plt.axvline(df_temp_desc["75%"], ls="--", color='b')
plt.show()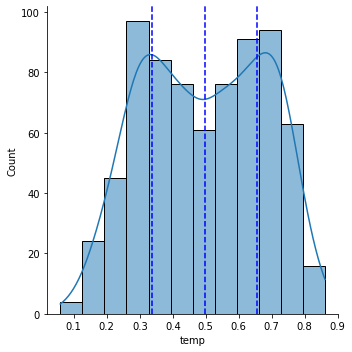
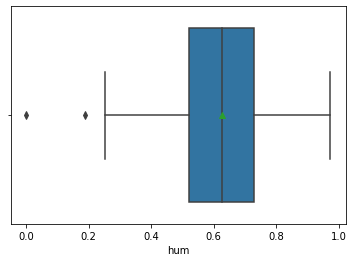
온도에 대한 분포는 확인했으니, 습도에 대한 분포도 확인해보겠습니다. 습도도 마찬가지로 Null값이 존재하지 않고 분포를 통해 중위수(50%)가 0.62임을 알 수 있습니다. 분포를 수치로 봤을때 살짝 우측으로 쏠린 느낌으로 보여지며 temp와는 분포가 다른 것을 확인할 수 있습니다.
>> df_day['hum'].describe()count 731.000000
mean 0.627894
std 0.142429
min 0.000000
25% 0.520000
50% 0.626667
75% 0.730209
max 0.972500
Name: hum, dtype: float64위 분포를 df_hum_desc라는 변수에 저장하였고, 습도도 온도처럼 쌍이 2개일수 있으니 분포에 대해 그래프를 그려서 확인해보겠습니다.
>> sns.displot(data = df_day, x = "hum", kde = True)
plt.axvline(df_hum_desc["25%"], ls="--", color='b')
plt.axvline(df_hum_desc["50%"], ls="--", color='b')
plt.axvline(df_hum_desc["75%"], ls="--", color='b')
plt.show()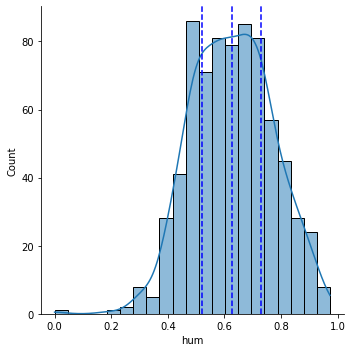
여기서 distplot과 히스토그램이란?
여기서 distplot이란 히스토그램을 그릴 수 있는 그래프입니다. 히스토그램을 통해 수치형 데이터 분포를 정확히 표현할 수 있습니다. 참고로 히스토그램을 그릴때 bins을 설정할 수 있는데 어느정도로 설정하느냐에 따라 분포를 해석하는게 달라질 수 있습니다. 어떤 데이터인가에 따라서 bins를 설정하는게 달라질 수 있습니다. 정답이 없는 것이다보니 데이터의 특성에 따라 적당한 bins를 나타내고 분포를 파악해야합니다.
더 자세한 distplot에 대해 알고싶다면 seaborn distplot을 참고해주세요 :)
temp의 분포를 확인했으니, 최대, 최소값, 퍼짐정도, 이상치여부를 파악하기 위해 평균값을 포함한 boxplot을 그려봅니다. temp에는 0.0591304 ~ 0.861667까지의 값이 들어가있으며 이상치는 없는 것으로 확인됩니다. 만약 이상치가 오른쪽에 분포되어있다면 데이터가 오른쪽에 치우쳐있다고 해석할 수 있습니다.
>> sns.boxplot(df_day['temp'], showmeans=True)
plt.show()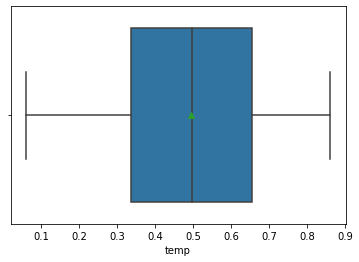
여기서 Boxplot이란?
한국어로 표현하면 상자수염그림이라고도 불리우는 boxplot은 최솟값, 제 1사분위, 제 2사분위, 제 3사분위, 최댓값으로 그려지는 그래프입니다. 박스 전체 부분은 주어진 분포의 사분위수 간 범위(IQR)을 의미합니다. 가장 좌측의 선은 최소값을, 우측의 선은 최대값을 나타냅니다. 위에서 describe()로 확인한 수치들을 그래프로 표현해서 5가지 요약 통계들을 한번에 보기 쉽게 표현 가능합니다. 왼쪽에 다이아몬드로 그려진 부분이 이상치이며 개인적으로 boxplot은 분포를 보기 위함도 있지만 이상치 확인용으로 많이 사용하는 것 같습니다.
이번 콘텐츠에서는 차근차근 처음보는 데이터를 확인하면서 상관관계, heatmap, distplot, 히스토그램, boxplot 등 그래프를 해석하고 수치를 이해하는 과정을 진행했습니다. 다음 콘텐츠에서는 이후의 데이터를 탐색하는 과정에 대해서 작성해보려고 합니다 :)
궁금한 부분이나 피드백 언제든 환영입니다! 다음 콘텐츠도 기대해주세요!
COCRE 2기 회원으로서 작성한 글입니다.

COCRE가 궁금하다면! 클릭!
'Dev > 데이터 분석' 카테고리의 다른 글
| [통계] 독립표본 t검정(t-test) (0) | 2023.02.28 |
|---|---|
| [데이터분석] 공유 자전거 데이터 분석(2편) (0) | 2022.08.31 |
| [데이터분석] 데이터 분석가는 어떤 일을 하나요? (0) | 2021.12.17 |
| [가설검정] P-value란?(어떤 사건이 우연히 발생할 확률) (2) | 2021.12.17 |
| [시각화] 주어진 데이터로 적합한 시각화하기 (0) | 2021.11.20 |



