안녕하세요! 코크리 크리에이터 김보경입니다🙋🏻♀️
모두가 할 수 있는 데이터분석 2편입니다!
지난 컨텐츠에서는 데이터의 구조와 명세에 대해서 간단하게 알아보고, 그래프를 그려 전체적인 분포와 수치를 해석하는 시간을 통해 boxplot에서는 정규분포를 따르는 것 처럼 보이지만 히스토그램을 그려서 쌍봉분포를 취하고 있다는 것을 확인했습니다.
이번편에서는 1편에서 다 파악하지 못한 데이터를 조금 더 탐색해보는 시간을 가지려고 합니다.
EDA(Exploratory Data Analysis, 탐색적 데이터 분석)
EDA란 데이터의 특징과 내재하는 구조적 관계를 알아내기 위해 시각화나 통계적 방법을 통해 다양한 각도에서 관찰하고 이해하는 과정을 말합니다. EDA 또한 정답이 없는 것이다보니 어떻게 시작할지 막막하다면 개별 변수의 분포(Variation) 그리고 변수간의 분포와 관계(Covariation)를 보는 것으로 시작하는 것도 좋습니다. 이런 분포 및 관계를 보기 위해서 지난편에서 설명했던 히스토그램, box plot, heatmap 그리고 Correlation 등 다양한 그래프를 사용할 수 있습니다.
조금 더 상세한 데이터를 탐색하기 위해서 빠르게 데이터전처리 작업을 진행하겠습니다. 데이터프레임의 범주형 컬럼들을 해당하는 의미의 이름으로 변경해주려고 합니다.
각 컬럼의 타입을 자세히 살펴보면 계절(season), 요일(weekday), 월(mnth), 상세날씨(weathersit)가 모두 범주형 컬럼임을 알 수 있습니다. (현재는 정수형)
>> df_day.dtypesinstant int64
dteday object
season int64
yr int64
mnth int64
holiday int64
weekday int64
workingday int64
weathersit int64
temp float64
atemp float64
hum float64
windspeed float64
casual int64
registered int64
cnt int64
dtype: object해당하는 정수값을 이해할 수 있는 문자형태로 변환해주고 바로 적용합니다.
>> df_day['season'].replace({1: 'spring', 2: 'summer', 3: 'fall', 4: 'winter'}, inplace =True)
df_day['weekday'].replace({0: 'Sunday', 1: 'Monday', 2: 'Tuesday', 3: 'Wednesday', 4: 'Thursday', 5: 'Friday', 6: 'Saturday'}, inplace =True)
df_day['weathersit'].replace({1:"Clear",2:"Cloudy",3:"LightRain",4:"Snow_Thunderstorm"}, inplace =True)
df_day['mnth'].replace({1:"Jan",2:"Feb",3:"Mar",4:"Apr",5:"May",6:"Jun",7:"Jul",8:"Aug",9:"Sep",10:"Oct",11:"Nov",12:"Dec"}, inplace =True)
범주형 변수
우선 계절과 날씨 변수를 대상으로 그래프를 그려보면 계절은 가을 시즌에 예약의 30% 이상이 발생했고, 가을, 여름, 겨울 순으로 예상과 다르게 봄에 이용한 건수가 가장 적은것으로 나타났습니다. 날씨 상황은 당연하게도 맑은날에 가장 많은 이용건이 발생했으며, 부분적으로 흐린 날씨인날에도 많이 이용했으며 그 다음으로는 약한 비나 눈이 내리는 경우에도 이용이 발생했고 폭우에는 1건의 이용도 발생하지 않은것을 확인할 수 있습니다. 아무래도 자전거다보니, 날씨는 사용자 수를 결정하는데 중요한 역할을 합니다. (계절과 날씨 변수는 예측 변수로 사용 예정)
>> fig, ax = plt.subplots(nrows = 1, ncols = 2, figsize = (25, 15))
ax[0] = sns.boxplot(x='season', y='cnt', data= df_day, ax=ax[0])
ax[1] = sns.boxplot(x='weathersit', y='cnt', data= df_day, ax=ax[1])
plt.show()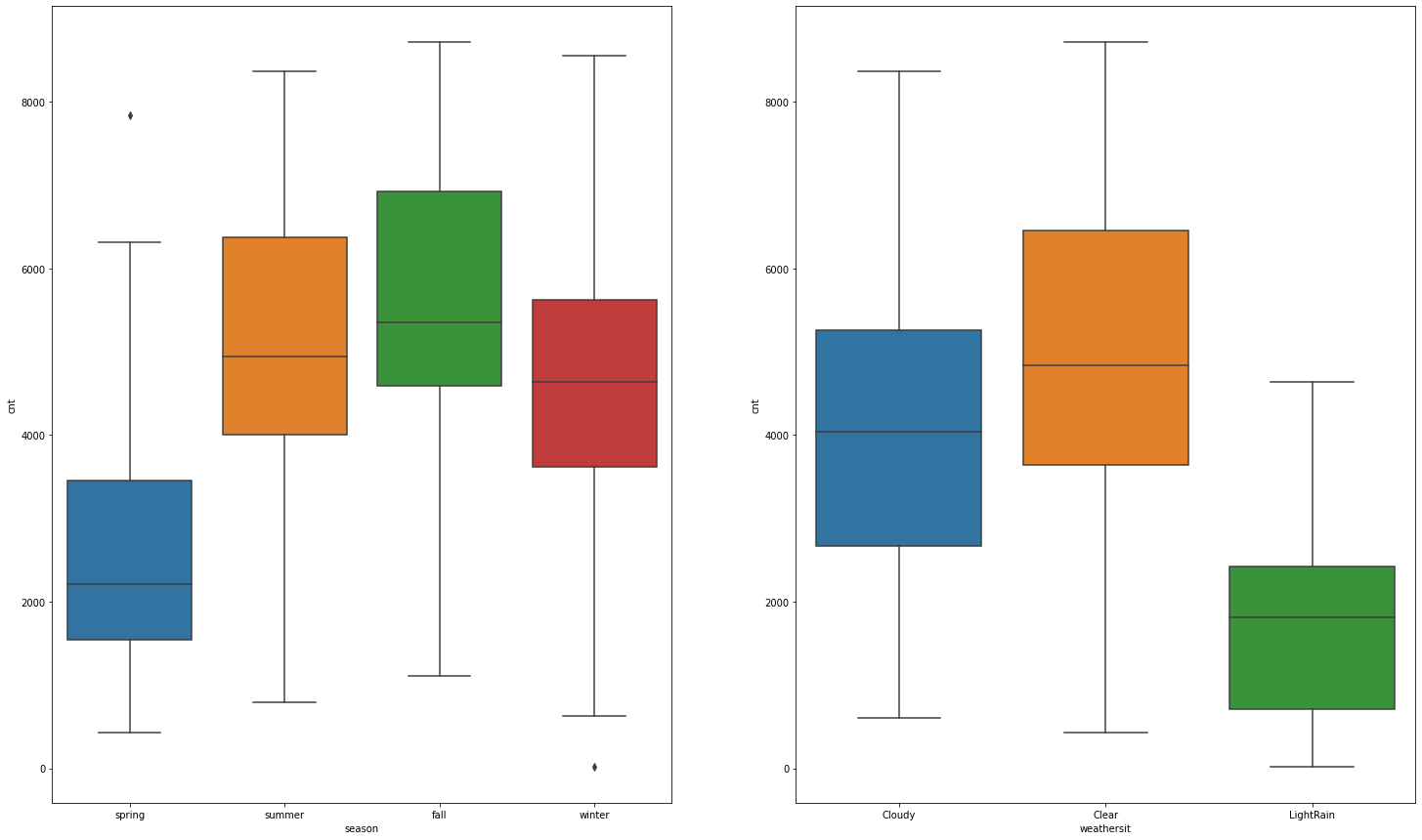
그 다음으로는 연도별, 월별로 확인해보았습니다. 연도(yr)는 2011년(0)과 2012년(1)이 있고, 2012년이 2011년보다 이용횟수가 더 많은 것을 확인할 수 있습니다. 우리가 예측하려고 하는 데이터도 2년치의 데이터이기 때문에 꽤 중요한 예측변수가 될 것 같습니다. 월별 변수는 패턴이 위 계절 변수에서 확인했던 것 처럼 가을에 이용건이 가장 높은 것을 확인할 수 있습니다. 5~10월의 중위수가 4000~5000건을 넘고 있으며 월별 또한 중요한 예측변수가 될 것 같습니다.
>> fig, ax = plt.subplots(nrows = 1, ncols = 2, figsize = (25, 15))
ax[0] = sns.boxplot(x='yr', y='cnt', data= df_day, ax=ax[0])
ax[1] = sns.boxplot(x='mnth', y='cnt', data= df_day, ax=ax[1])
plt.show()
이제 요일별, 휴일, 근무일에 대한 데이터를 확인해보겠습니다. 요일별로 확인했을때 비슷한 산포를 나타내고 있고 명확한 패턴이 보이지 않으므로 예측 변수로 사용하기엔 적합하지 않을 것 같습니다. 휴일 또한 평일 710건, 휴일 21건으로 예약의 97%이상이 평일에 발생했습니다. 해당 변수 또한 편향되어 있는 값이기 때문에 예측변수로 사용하기 적합하지 않을 것 같습니다. 근무일은 근무하는날 예약건 500건, 근무하지 않는날 231건으로 예약의 68% 가량이 근무하는날에 발생했고, 여부 값의 중위수가 5000건에 비슷하게 분포하고 있습니다. 해당 변수는 예측변수로 활용해도 좋을 것 같습니다.
>> fig, ax = plt.subplots(nrows = 1, ncols = 3, figsize = (25, 10))
ax[0] = sns.boxplot(x='weekday', y='cnt', data= df_day, ax=ax[0])
ax[1] = sns.boxplot(x='holiday', y='cnt', data= df_day, ax=ax[1])
ax[2] = sns.boxplot(x='workingday', y='cnt', data= df_day, ax=ax[2])
plt.show()
수치형 변수
이제 수치형 변수의 분포와 상관관계를 확인해보겠습니다. 각 변수들의 관계를 살펴보니 온도들(정상 온도, 섭씨로 정규화된 온도)과 이용건수와는 선형관계가 있음을 알 수 있습니다. 그리고 온도가 상승할수록 이용건수도 높아지는 것을 볼 수 있으며, 풍속이 빨라질수록 탑승자 수가 줄어드는 것도 확인할 수 있습니다. 지난편에서 확인했던 것 처럼 연도와 탑승자 수 사이에 양의 상관관계가 있던 것과, 온도들(정상 온도, 섭씨로 정규화된 온도) 또한 상관관계가 높았던 것도 해당 그래프와 함께 생각해볼 수 있습니다. 온도들 같은 경우에는 서로 상관관계가 매우 높기 때문에 하나의 변수만 선택해서 사용하는 것이 좋을 것 같습니다.
>> sns.pairplot(df_day[['temp', 'atemp', 'hum', 'windspeed','cnt']], diag_kind='kde')
plt.show()
해당 그래프를 1개의 온도(temp)와 습도(hum), 풍속(windspeed)을 기준으로 연도별(yr), 근무여부(workingday)에 따라 조금 더 상세히 살펴보겠습니다.
우선 연도별로 나눠서 확인해보면 연도별 분포는 비슷하고 몇 아웃라이어들을 제외하고는 크게 차이나는 부분이 존재하지는 않습니다.
>> sns.pairplot(data=df_day, vars=['temp', 'hum', 'windspeed'], hue='yr', diag_kind='kde', markers=['.', '*'], kind='reg', size = 3)
plt.show()
근무여부(workingday)를 기준으로 확인해보면, 각 변수별 관계는 연도별로 확인했던 분포와 크게 다르지 않다는 것을 확인할 수 있고, 근무 여부에 따라 각 변수의 온도, 습도, 풍속이 다르다는 것을 파악할 수 있습니다.
>> sns.pairplot(data=df_day, vars=['temp', 'hum', 'windspeed'], hue='workingday', diag_kind='kde', markers=['.', '*'], kind='reg', size = 3)
plt.show()
시계열 흐름을 보기 위해서 일자별로 이용건수를 살펴보겠습니다. 일자별, 연도별로 이용건수를 그룹화해줍니다.
>> df_ts = df_day[['dteday', 'cnt', 'yr']]
df_ts_agg = df_ts.groupby(['dteday', 'yr']).agg({'cnt':'sum'}).reset_index()
df_ts_agg
코드가 조금 길어졌지만 2011, 2012를 같은 형태로 확인하기 위해 임의로 2000년으로 변경해주고, 시계열 그래프를 그려봅니다. yr이 0인 2011년과 1인 2012년을 분리하여 그려주고 이용건수를 x축기준 일주일 간격으로 나타냅니다. 트랜드를 살피면 2011년보다 2012년의 이용건수가 확연히 높으며 특정일자에 급격히 이용건이 떨어지는 부분이 존재합니다.
>> from matplotlib import dates
df_ts_agg['dt'] = df_ts_agg['dteday'].map(lambda x: x.replace(year=2000))
fig, ax = plt.subplots(figsize=(30, 13))
sns.lineplot(df_ts_agg[df_ts_agg['yr']==0]['dt'], df_ts_agg[df_ts_agg['yr']==0]['cnt'], label="2011")
sns.lineplot(df_ts_agg[df_ts_agg['yr']==1]['dt'], df_ts_agg[df_ts_agg['yr']==1]['cnt'], label="2012")
ax.xaxis.set_major_locator(dates.DayLocator(interval=7))
ax.xaxis.set_major_formatter(dates.DateFormatter('%m-%d'))
plt.xticks(rotation=90)
plt.show()
이번편은 EDA를 통해 지난편에서 깊게 확인하지 못했던 데이터를 탐색하는 시간을 가졌습니다. 다음 컨텐츠에서는 여러 모델을 사용해서 자전거의 이용량을 예측해볼 예정입니다 :)
궁금한 부분이나 피드백 언제든 환영입니다! 다음 콘텐츠도 기대해주세요!
COCRE 2기 회원으로서 작성한 글입니다.

COCRE가 궁금하다면! 클릭!
'Dev > 데이터 분석' 카테고리의 다른 글
| [통계] 카이제곱 검정(두 변수간 관계파악) (0) | 2023.05.01 |
|---|---|
| [통계] 독립표본 t검정(t-test) (0) | 2023.02.28 |
| [데이터분석] 공유 자전거 데이터 분석(1편) (0) | 2022.06.30 |
| [데이터분석] 데이터 분석가는 어떤 일을 하나요? (0) | 2021.12.17 |
| [가설검정] P-value란?(어떤 사건이 우연히 발생할 확률) (2) | 2021.12.17 |



