
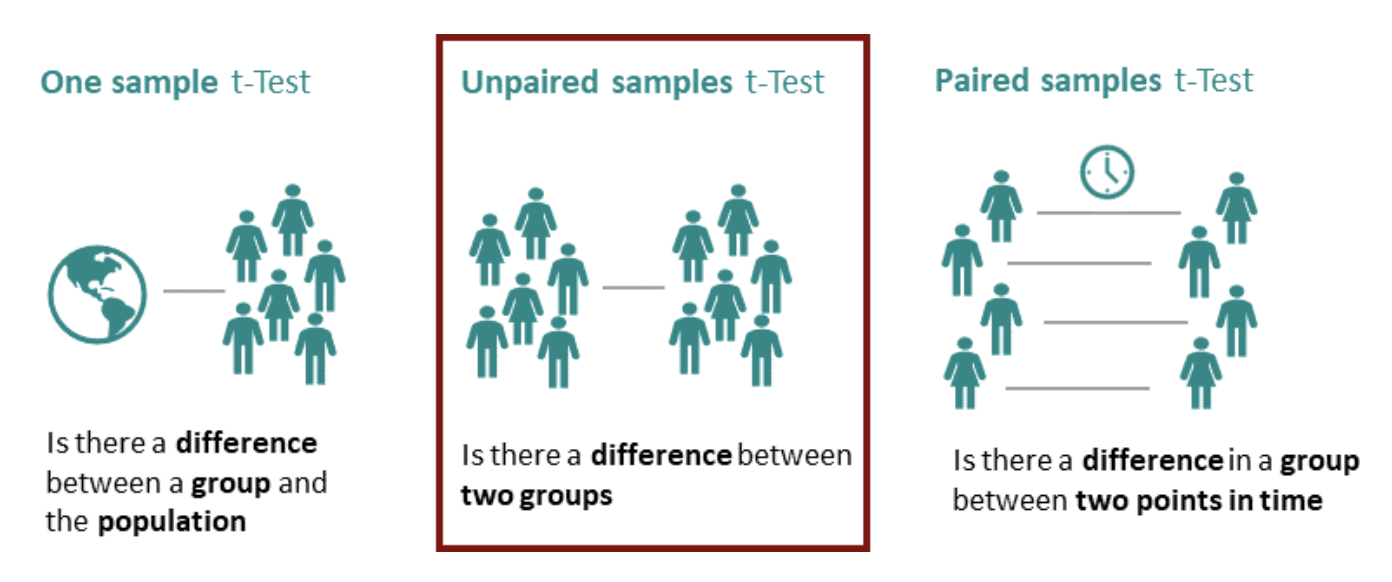
독립표본 t 검정
: 서로 독립인 두 모집단의 모평균이 동일한지의 여부를 검정하기 위한 검정통계량
각 모집단으로부터 추출된 독립표본을 이용할 수 있습니다
가설의 채택 및 기각은 P-value를 기반으로 정해지기때문에 꼭 P-value에 대한 개념을 이해한 뒤 읽어주시면 좋습니다 :)
2021.12.17 - [Dev/데이터 분석] - [가설검정] P-value란?(어떤 사건이 우연히 발생할 확률)
[가설검정] P-value란?(어떤 사건이 우연히 발생할 확률)
통계의 기본 P-value 편! 통계를 공부하다보면 P-value에 따라 이 값은 유의하다, 유의하지 않다를 판단하는데 도대체 P-value가 무엇일까요? [이미지 링크] 어떤 사건이 우연히 발생할 확률이 얼마일
bodi.tistory.com
T-test란?
가설검정의 한 종류로 모집단의 분산, 표준편차를 알 수 없을때 표본으로부터 추정된 분산, 표준편차를 이용하여 두 모집단의 평균차이를 통해 집단이 같은지, 다른지 알아보는 검정방법입니다. T-test는 아래의 가정을 만족해야합니다.
가정
- 독립성
- 두 집단을 구성하는 변수가 서로 관계가 없는 것.
- 예) 제조국 미국, 유럽은 서로 관계가 없는 상태
- 정규성
- 정규분포를 만족해야한다.
제조국에 따른 가속도 차이
제조국이라는 독립변수(범주형)에 따른 가속도(연속형)의 차이를 보고싶을때 주로 T-test를 사용합니다. 집단의 수가 3개이상인 경우 ANOVA 검정을 사용합니다.
그럼 바로 예시로 넘어가보겠습니다. seaborn 모듈에 mpg 데이터셋을 활용하여 제조국(origin) 중 미국(usa)과 일본(japan)의 가속도(acceleration)의 평균에 차이가 있는지 확인해보겠습니다.
0) 가설 설정
귀무가설 : 미국과 일본의 가속도(acceleration)에 차이가 있다.
대립가설 : 미국과 일본의 가속도(acceleration)에 차이가 없다.
1) 모듈 및 데이터 import
import seaborn as sns
from scipy.stats import shapiro
from scipy.stats import levene
from scipy.stats import ttest_ind
df = sns.load_dataset('mpg')
df.head()
2) 컬럼 정보 확인
우리가 확인할 컬럼의 타입을 먼저 확인해줍니다. 간혹 숫자값으로 들어가있지만 타입을 확인해보면 문자열인 형태로 구성되어있을 수 있습니다.
df.info()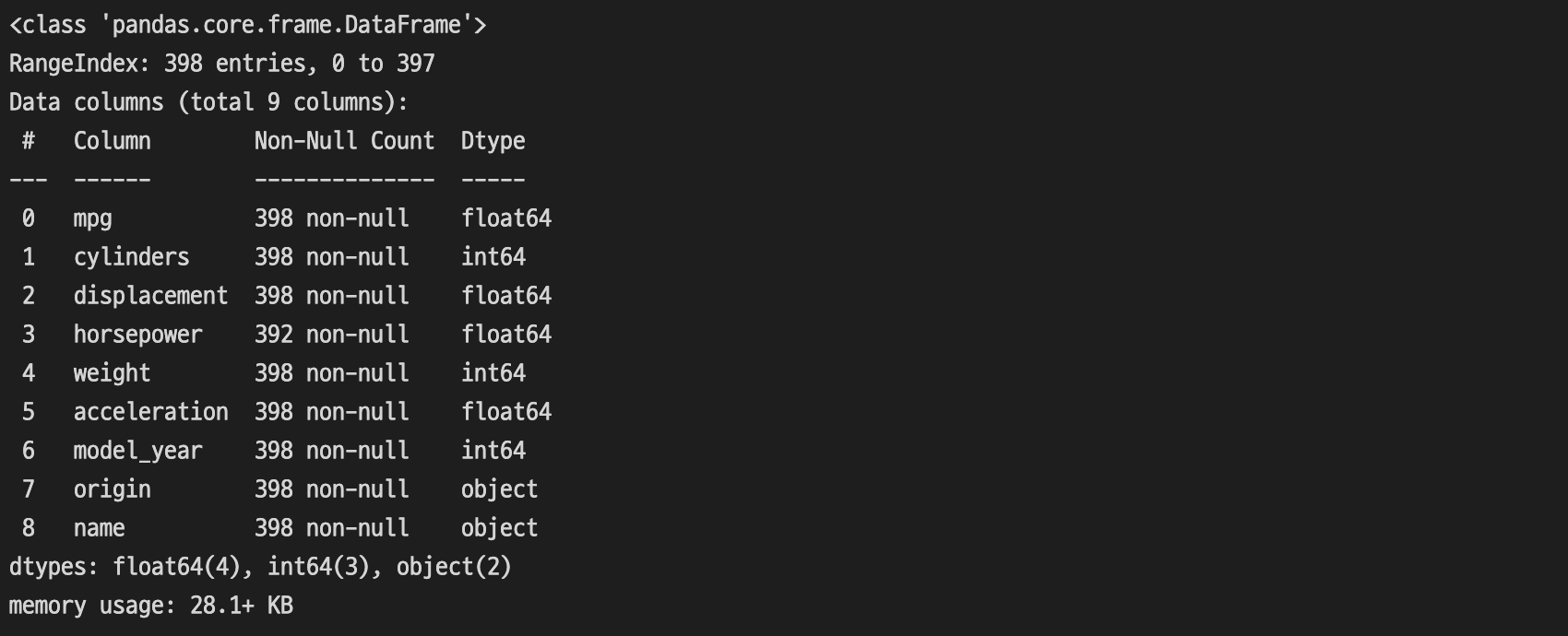
3) 제조국별 가속도 분리
제조국이 미국(use)인 데이터의 가속도(acceleration)를 df_usa에, 일본(japan)인 데이터의 가속도(acceleration)를 df_usa, df_japan에 대입해줍니다.
df_usa = df.loc[df['origin']=='usa', 'acceleration']
df_japan = df.loc[df['origin']=='japan', 'acceleration']
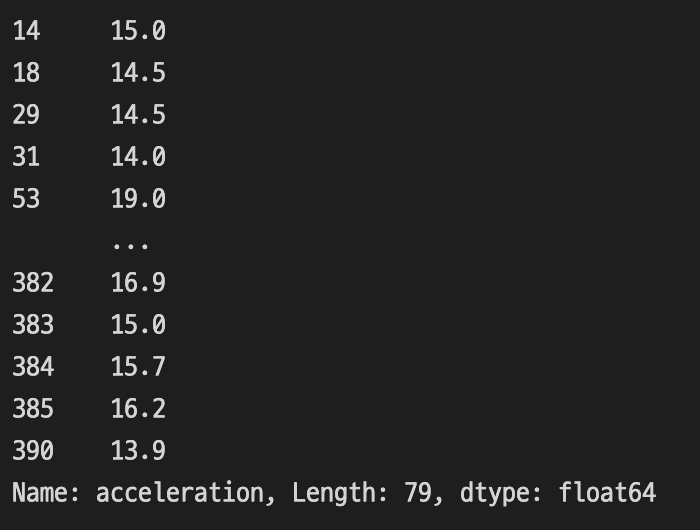
4) 데이터 확인
df_usa df_japan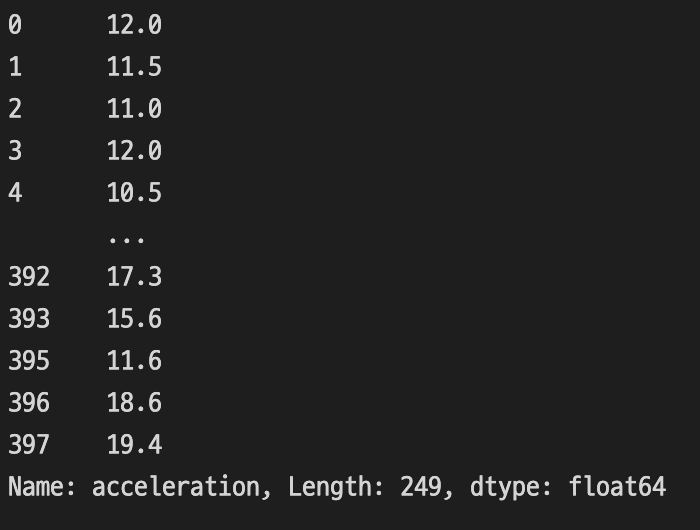
5) 정규성 검정
독립표본 t-검정전 위 가정을 만족하는지 확인해줍니다. python에서 Scipy를 사용해서 한줄로 확인이 가능합니다. 입력 자료의 정규성의 가정을 확인하기 위한 shapiro() 함수는 scipy.stats 모듈에서 불러올 수 있습니다.
(자세한 내용은 scipy 홈페이지 참조)
shapiro(df_usa)
shapiro(df_japan)
P-value의 값이 0.6593, 0.5289로 나타나 정규성을 가진다는 것을 확인할 수 있습니다. (가정 만족)
6) 등분산 검정
두 집단의 자료가 등분산의 가정을 만족하는지 확인하기 위한 levene() 함수도 scipy.stats 모듈에서 불러올 수 있습니다. levene 검정을 통해 독립인 두 집단의 자료가 독립인 경우 equal_var 옵션에 True를 입력하고, 독립이 아닌 경우 False를 입력해줍니다.
levene(df_usa, df_japan)
미국의 가속도, 일본의 가속도 데이터로 등분산 검정을 실시한 결과 P-value 값이 0.0031로 등분산성 가정을 만족하지 못하는 것을 확인할 수 있습니다.
7) T-test
scipy.stats 모듈에서 ttest_ind() 함수를 불러와서 독립표본 t 검정을 실시합니다. 위에서 등분산 가정을 만족하지 못했기 때문에 equal_var 옵션에 False를 입력합니다.
ttest_ind(df_usa, df_japan, equal_var= False)
독립표본 t 검정 실시 결과 P-value는 0.05보다 작기 때문에 미국과 일본의 가속도에는 차이가 존재한다는 것을 알 수 있습니다.
여기까지 독립표본 t검정에 대해서 알아봤습니다.
서로 독립인 두 모집단의 모평균이 동일한지 확인하는 독립표본 t검정 조금 감이 잡히시나요?
조금 더 알차고 자세한 컨텐츠로 돌아올게요! 읽어주셔서 감사합니다 😄
(잘못된 개념이나 피드백은 언제든 환영입니다)

'Dev > 데이터 분석' 카테고리의 다른 글
| [지표] 임팩트 있는 문제를 정의하려면? (2) | 2023.09.30 |
|---|---|
| [통계] 카이제곱 검정(두 변수간 관계파악) (0) | 2023.05.01 |
| [데이터분석] 공유 자전거 데이터 분석(2편) (0) | 2022.08.31 |
| [데이터분석] 공유 자전거 데이터 분석(1편) (0) | 2022.06.30 |
| [데이터분석] 데이터 분석가는 어떤 일을 하나요? (0) | 2021.12.17 |



